



You're probably dealing with a familiar tension. The product wants a faster release. Clinical stakeholders want less friction. Legal wants confidence that patient data won't become tomorrow's incident report. Engineering is caught in the middle, trying to ship something useful without creating a long-term security liability.
That tension is exactly where secure healthtech applications are won or lost.
The teams that struggle usually don't fail because they skipped encryption. They fail because security work stayed fragmented. Compliance sat in one document, architecture decisions lived somewhere else, vendor reviews happened late, and incident response only became real after a scare. In healthtech, that approach breaks down fast, especially when your application handles sensitive patient information, connects to external systems, or operates across Canadian and cross-border environments.
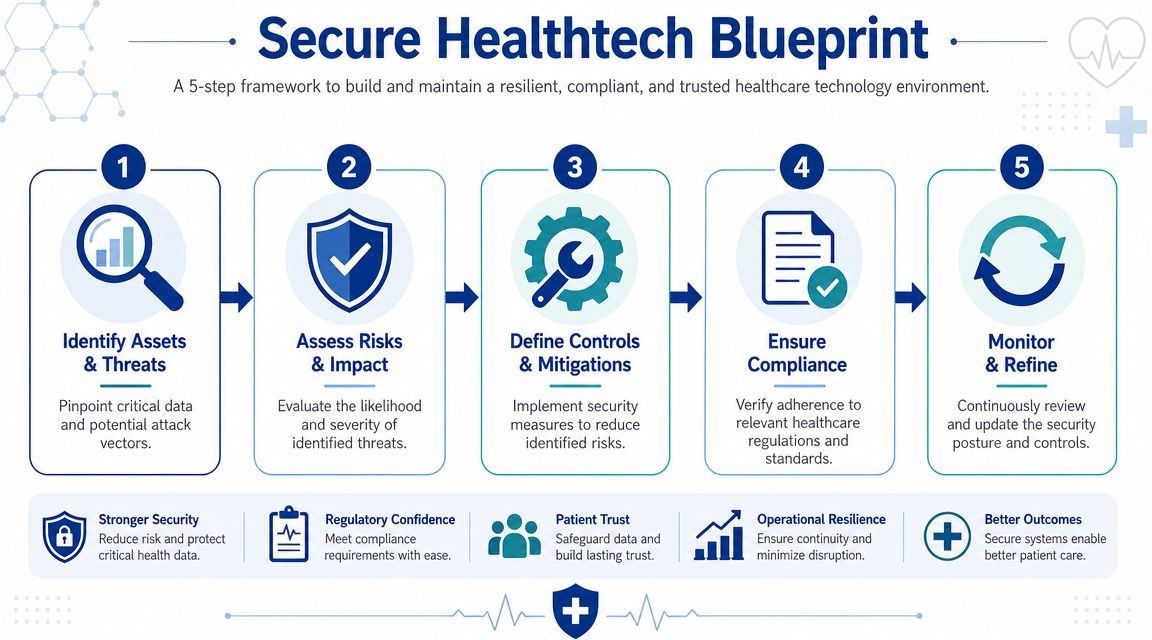
A stronger approach is lifecycle-based. Security starts before code, continues through architecture and delivery, and stays active in operations, support, and product design. That's how teams build applications that can stand up to technical scrutiny, regulatory expectations, and real-world user behaviour.
Laying the Foundation With Threat Modelling and Compliance
A healthtech product can look ready for launch and still be one architecture decision away from a reportable breach. I usually see the problem earlier, during planning, when no one has pinned down what data enters the system, which jurisdictions apply, where the trust boundaries sit, or who owns response decisions if something goes wrong.
That foundation work is where secure healthtech applications either become governable or drift into expensive rework. In Canadian and cross-border environments, security planning has to connect privacy obligations, engineering decisions, vendor usage, and operational response from the start.
In Canada, the legal baseline shows up early. PIPEDA applies to many organisations handling personal information in the course of commercial activity, and the federal regime also requires breach reporting and recordkeeping in certain cases involving a real risk of significant harm, as outlined by the Office of the Privacy Commissioner of Canada (PIPEDA breach guidance). For digital health vendors, that means compliance cannot sit in a policy binder while architecture moves ahead on a separate track.
Start With the Data, Not the Feature List
The first useful design question is simple: what information does this release need?
Teams often over-collect in the name of future product flexibility. In practice, that creates more retention, more access pathways, more logging exposure, more vendor review work, and more breach impact if a control fails. A better starting point is privacy by design with data minimisation. Define the minimum personal and clinical data required for the workflow, map where it is created, viewed, transmitted, stored, and deleted, and then decide which controls belong at each step.
For cross-border products, that mapping also forces the right regulatory conversations early. If a Canadian platform serves U.S. entities, or uses U.S.-hosted subprocessors, the team needs a clear view of which obligations come from Canadian privacy law, which come from contracts, and which come from frameworks such as HIPAA that customers may expect you to align with even when they do not apply directly to your whole business.
One rule is worth stating plainly.
Practical rule: If a release can work without storing a category of PHI, do not store it yet.
Threat Modelling That Reflects Actual Healthtech Risk
Healthtech threat modelling works best when it stays close to the product, not at the level of generic risks such as "data breach" or "unauthorised access." Those labels are too broad to guide engineering decisions.
Break the system into trust boundaries, user roles, and sensitive actions. That usually means looking at patient and clinician workflows, support tooling, admin paths, APIs, background jobs, third-party integrations, and any process that exports or transforms data. Then ask concrete questions.
Who are the actors: Patients, clinicians, support staff, finance teams, integration partners, vendors, and internal administrators.
What are the assets: Clinical notes, intake data, claims data, identifiers, access tokens, audit trails, consent records, and configuration secrets.
Where are the trust boundaries: Device to app, app to API, API to data store, workload to vendor service, support console to production environment.
What can fail in realistic ways: Account takeover, privilege creep, token leakage, insecure exports, broken consent enforcement, weak tenant isolation, excessive retention, and unsafe admin tooling.
This exercise should produce decisions, not just diagrams. It should change backlog priority, data model design, logging scope, and release criteria. If the output never affects implementation, the team has created paperwork, not a threat model.
Translate Obligations Into Engineering Controls
Compliance language is usually broad. Engineering work cannot be.
A simple mapping exercise keeps legal and technical teams aligned, especially when the product operates across provinces or crosses into U.S. customer environments.
| Compliance concern | Technical interpretation |
|---|---|
| Limit collection | Remove unnecessary PHI fields and optional sensitive inputs |
| Safeguard data | Encrypt data in transit and at rest, protect keys and secrets, and restrict data exports |
| Restrict access | Role-based access control, approval for elevated privileges, session controls, strong authentication |
| Accountability | Audit logging, admin activity trails, retention rules, evidence for reviews |
| Breach readiness | Incident playbooks, escalation paths, forensic logging, notification workflow |
Teams that need a structured way to connect those requirements often benefit from a compliance-driven software development approach because it brings legal, product, security, and engineering into the same delivery process instead of leaving each group to interpret obligations on its own.
What Works in Practice
The strongest teams write a short security blueprint before development starts. It does not need to be long. It needs to be specific.
At minimum, it should define data classes, approved data flows, role definitions, trust boundaries, logging scope, vendor dependencies, hosting assumptions, and breach ownership. It should also record the trade-offs. For example, a team may accept temporary manual review for a sensitive workflow rather than automate it too early and widen access to PHI. That is a real design decision. It belongs in the blueprint.
What fails is the opposite pattern: a spreadsheet of regulations, a generic risk register, and no architectural consequence. In healthtech, especially in Canadian and cross-border deployments, that gap shows up later as delayed audits, rushed vendor reviews, access model rewrites, and incident response plans built after production data is already live.
If your threat model does not change what you build, it is not doing its job.
Architecting for Security With Data Protection and IAM
Once the foundation is clear, architecture decisions start carrying most of the security weight, determining whether secure healthtech applications become resilient by default or fragile behind a thin layer of controls.
The easiest way to think about it is this: data protection is the vault, identity and access management is the gatekeeper, and network controls reduce unnecessary exposure between the two.
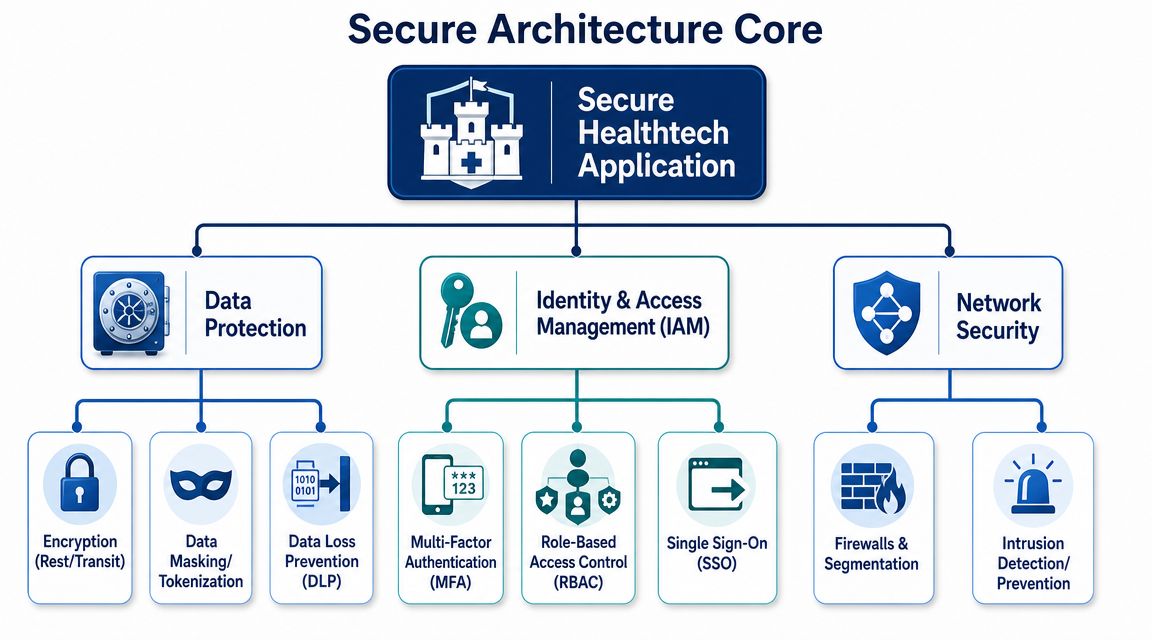
Protect the Data According to How It’s Used
Not every protection mechanism solves the same problem. Teams get into trouble when they treat encryption, hashing, and tokenisation as interchangeable.
Here's the practical distinction:
| Method | Best use | Not a substitute for |
|---|---|---|
| Encryption | Data that must be read later by authorised systems or users | Access control |
| Hashing | Password storage, integrity checks | Reversible storage |
| Tokenisation | Replacing sensitive values in workflows, logs, or downstream systems | End-to-end encryption |
For example, patient profile data in a database may need encryption because the system must retrieve it. Passwords should be hashed, not encrypted. Sensitive identifiers sent into analytics, support tools, or test systems may be better tokenised so the downstream tool never receives the original value.
IAM Fails More Often in the Role Model Than in the Login Screen
Many teams implement sign-in correctly and still expose too much. The weak point is usually authorisation, not authentication.
Role-based access control sounds simple until you model a real clinic or payer workflow. Reception staff need different access than clinicians. Support agents may need limited access to troubleshoot without seeing full records. Internal operations staff may need broad environment permissions but no patient-level visibility. If those distinctions aren't explicit, people end up sharing workarounds or accumulating access they no longer need.
A usable IAM model for healthtech should include:
Role definitions tied to job function: Not vague labels like “standard user”.
Least-privilege defaults: Access starts narrow and expands only with a documented need.
Separation for admin actions: Production support, security administration, and data export shouldn't sit in one catch-all superuser role.
Session and token controls: Short-lived sessions for sensitive workflows, re-authentication for high-risk actions, and strong token handling.
Joiner, mover, leaver discipline: Access should change when a person changes role, not months later.
Strong authentication can still protect an over-permissioned system badly.
Design Patterns Worth Using Early
The architecture choices that save the most pain are rarely flashy.
Encrypt by service boundary: Protect data in transit between services, not only at the browser edge.
Keep PHI out of logs: Logging frameworks often capture request payloads unless you deliberately suppress or mask them.
Isolate sensitive workloads: Admin consoles, reporting jobs, and clinical APIs shouldn't all share the same blast radius.
Make access review possible: If your permissions model is too complex to review, it's too complex to trust.
Use environment separation properly: Test and staging environments shouldn't become quiet replicas of production risk.
Where Teams Overbuild and Underbuild
Overbuilding usually means piling on controls that look strong on paper but break workflow. A good example is forcing repeated step-up authentication for routine clinician tasks with no risk differentiation.
Underbuilding is more common. Teams encrypt databases but ignore exports, background jobs, support dashboards, and internal tooling. That leaves data protected at rest while remaining exposed everywhere people access it.
This is why architecture has to reflect user paths, not just infrastructure diagrams. In secure healthtech applications, the dangerous gap is often between the primary product and the operational tools around it.
Securing the Ecosystem Through APIs and Vendor Risk Management
A standalone app is simpler to defend. A connected healthtech platform is not. Once your product exchanges data with EHRs, insurers, labs, messaging providers, analytics tools, or document services, the security question shifts from “is the app hardened” to “is the ecosystem governed”.
That shift matters because modern health apps are increasingly framed around real-time, consented health data access, including categories such as AI-driven patient support and prior authorisation workflows. The practical implication is that security now depends on identity, consent, data sharing, token and session protection, granular authorisation, data-flow mapping, and third-party monitoring, not only app-level controls (CMS health technology ecosystem categories).
API Security Breaks at the Seams
Most API incidents don't come from a missing firewall rule. They come from a mismatch between what the API exposes and what the business intended to allow.
Common examples include:
Overbroad scopes: One token opens far more patient or operational data than the client needs.
Weak object-level authorisation: The user is authenticated, but the API doesn't verify they're allowed to access that specific record.
Consent drift: The system records consent at intake but doesn't enforce it consistently across downstream requests.
Unsafe token handling: Long-lived tokens, poor revocation discipline, or token leakage into logs and browser storage.
Silent dependency risk: External SDKs and middleware sit on critical paths with little ongoing scrutiny.
In healthcare integrations, this gets sharper because APIs often carry workflow authority, not just data access. An endpoint may trigger prior authorisation, retrieve chart context, initiate communication, or pass patient-entered information into a clinical system. Each action needs both technical protection and business-rule enforcement.
A Review Model That Works in Practice
When teams are integrating health ecosystems, I prefer a short pre-integration checklist before any connector moves to build:
| Area | Questions to answer |
|---|---|
| Identity | Who is the calling party, and how is it verified? |
| Authorisation | What exact records or actions can that party access? |
| Consent | Where is consent stored, checked, and revoked? |
| Data minimisation | What fields are actually required for the workflow? |
| Logging | Which events will be logged without exposing sensitive content? |
| Failure modes | What happens if the partner API degrades, misroutes, or returns unexpected data? |
For teams working on interoperability-heavy products, healthcare API integration patterns are worth reviewing early because they force these questions before the contract is signed and the technical debt is locked in.
Vendor Risk Is Architecture Risk
Third-party risk reviews are often treated like procurement paperwork. That's too late and too shallow.
A vendor handling messages, analytics, hosting, transcription, support operations, or embedded functionality can change your threat surface immediately. Review vendors according to the role they play in your system.
Focus on three things:
What data they touch: Direct PHI, derived data, metadata, or no patient data at all.
What authority they hold: Read, write, admin, token issuance, backup, monitoring, or support access.
How failure propagates: Confidentiality loss, integrity issues, service disruption, or broken auditability.
If a vendor can affect patient data, access, or availability, they're part of your security architecture, whether you planned for it or not.
The strongest teams assign clear ownership for every integration and every vendor. Someone must know what the connection does, what the dependency can access, what normal behaviour looks like, and how to suspend it safely if needed. Without that, your platform may be secure internally but exposed through the exact systems it depends on to function.
Embedding Security Into Your Workflow With DevSecOps
Security reviews that happen at the end of delivery create the same pattern every time. Engineers rush to patch findings. Product argues over timelines. Security teams get framed as blockers. Nobody trusts the process.
A healthier model is DevSecOps, where controls live inside the delivery workflow instead of being bolted on after features are already shaped. In practice, that means development teams get fast feedback on security issues while the code is still cheap to change.
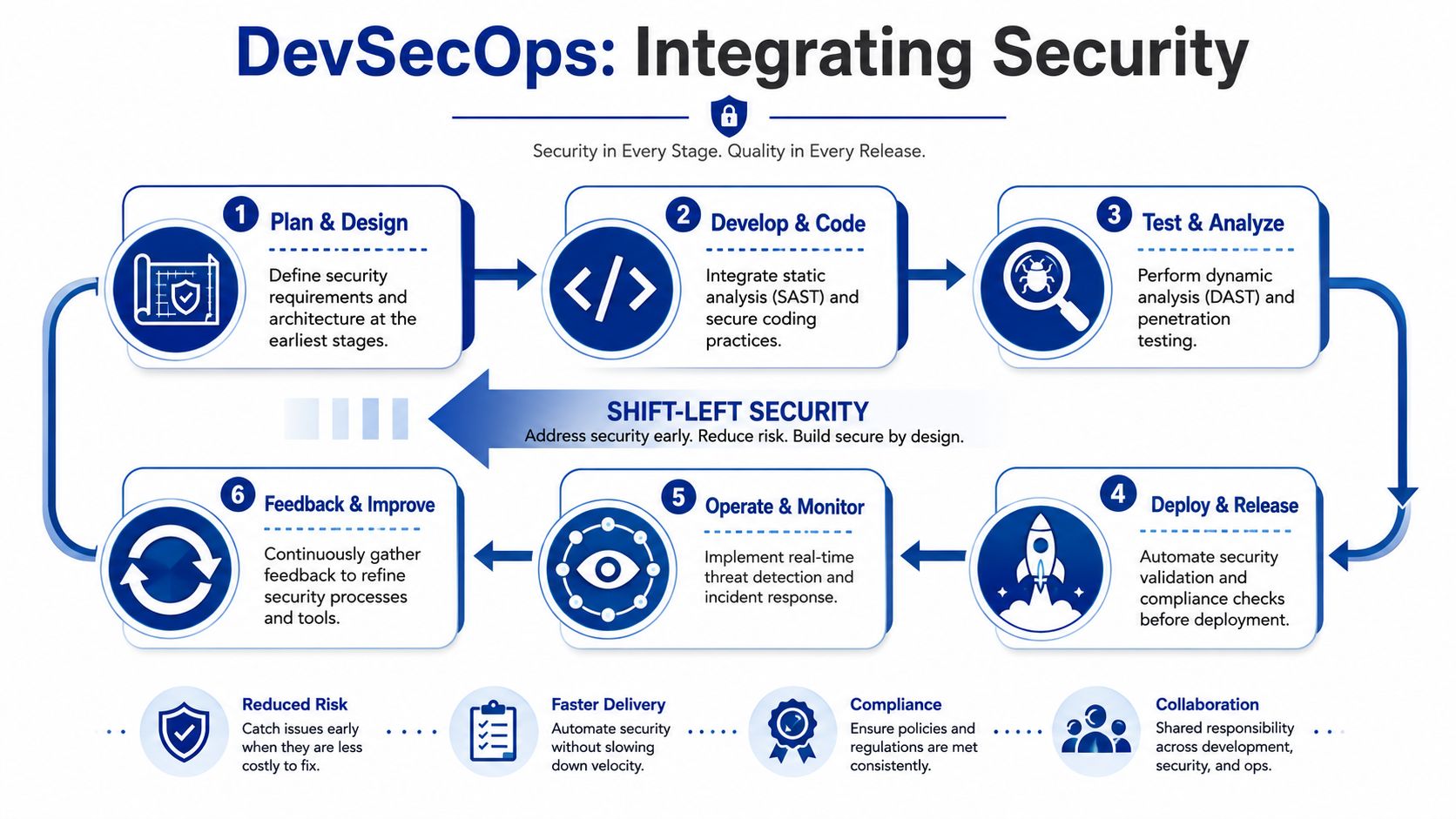
Treat the Pipeline as a Control Surface
A modern healthtech pipeline should enforce decisions, not just run builds. If the pipeline only compiles code and deploys containers, security still depends on memory and goodwill.
A stronger pipeline usually includes these gates:
Pre-Commit and Pull Request Checks
Secrets scanning, linting for secure coding patterns, and peer review for risky changes such as auth logic, file upload handlers, and export functions.Static Analysis During Build
SAST tools catch insecure patterns in code before runtime. They're especially helpful for injection risks, weak input handling, and unsafe use of crypto libraries.Dependency and Container Scanning
Open-source packages and base images create a large share of avoidable risk. Scan them continuously, not just at release time.Infrastructure-As-Code Validation
Cloud security misconfigurations often start in templates and deployment scripts. Validate those artefacts before they reach an environment.Dynamic Testing in a Running Environment
DAST helps identify issues that only appear when the application is live, such as session handling flaws, exposure through routes, or insecure headers and redirects.Release Approval Based on Risk
Not every finding needs the same treatment. Build a triage model so critical issues block releases, while lower-risk items are tracked with explicit ownership.
Tooling Matters, but Workflow Matters More
Teams often ask which tools to adopt first. The answer depends on stack and maturity, but the order of operations matters more than any brand choice.
A practical rollout usually looks like this:
Start with secrets scanning and dependency review. Those controls catch common, high-impact mistakes with relatively low friction.
Add SAST with tuned rules. Untuned tools create alert fatigue fast. Start narrow, calibrate, and expand.
Bring in DAST for exposed applications and APIs. Use authenticated scans where possible so testing reflects real attack surfaces.
Review infrastructure definitions. Terraform, cloud templates, Kubernetes manifests, and policy definitions deserve the same scrutiny as application code.
Use manual testing for high-risk paths. Authentication, authorisation, billing flows, data export, and admin functions still need human review.
Penetration Tests Deliver Value When You Prepare for Them
A pentest is not a substitute for engineering discipline. It's a focused assessment of a point in time.
You get the most value when the environment is stable, test accounts are realistic, logging is enabled, and the team is ready to reproduce and fix findings quickly. Without that, the report may be technically accurate but operationally weak.
A few preparation steps help:
Define scope precisely: Include APIs, admin functions, mobile endpoints, third-party integrations, and privileged roles.
Provide safe but realistic test data: Enough to exercise workflows without creating avoidable exposure.
Have engineering ownership ready: Someone must triage findings immediately and decide whether they reflect code defects, design flaws, or configuration issues.
Retest fixes: Closure matters more than report delivery.
For teams formalising this discipline, a documented DevOps pipeline build process can help security, development, and operations work from the same release model. If you need implementation support, Cleffex Digital Ltd is one example of a provider that builds custom healthcare software and application delivery workflows, but the principle applies regardless of partner choice.
What Mature Teams Do Differently
They don't ask security to approve everything manually. They encode repeatable checks into the pipeline, reserve human review for the hardest risks, and keep a clear exception process for urgent releases.
That balance matters. In secure healthtech applications, the goal isn't to slow delivery. It's to make unsafe delivery harder than safe delivery.
Maintaining Operational Defence and Incident Response
Launch day doesn't close the security project. It changes the job.
Once a healthtech application is live, the threat model stops being hypothetical. You now have active users, production credentials, support processes, integrations, backups, and operational shortcuts creeping in under time pressure. That's why the post-launch phase determines whether your controls survive contact with reality.
Monitoring Must Tell You What Matters
Many teams collect logs. Far fewer can answer a simple question during an incident: what happened, who did it, what data was involved, and what changed?
Useful operational logging in healthtech usually includes:
Authentication events: Successful and failed logins, MFA challenges, password resets, and session revocations.
Authorisation changes: Role assignments, privilege elevation, and admin approvals.
Data access events: Exports, bulk retrieval, sensitive record views, unusual query patterns.
Configuration changes: IAM updates, network policy changes, storage rule changes, and feature-flag changes affecting security.
Integration activity: Token issuance, third-party API failures, unusual request bursts, revoked client activity.
If logs don't support investigation, they're just storage consumption.
Your logging design should make incident reconstruction possible without exposing the very PHI you're trying to protect.
Hardening Production Needs Discipline, Not Heroics
Operational defence usually fails through convenience. Shared admin accounts linger. Temporary access becomes permanent. Debug settings remain enabled. Backups exist, but nobody tests restoration under pressure.
A healthy production posture usually includes a few essential requirements:
| Operational area | What good looks like |
|---|---|
| Admin access | Individual accounts, strong authentication, controlled elevation |
| Environment hygiene | Segregated environments, no casual production access from development workflows |
| Secrets management | Centralised handling, rotation process, minimal human exposure |
| Change control | Security-sensitive changes reviewed and logged |
| Backup strategy | Protected backups, restoration rehearsed, dependency mapping documented |
For backup resilience, it's sensible to study approaches such as immutable backup solutions from ARPHost, LLC, because recovery planning is part of security, not only infrastructure. If ransomware, malicious deletion, or operator error hits a critical health workflow, recovery integrity matters as much as perimeter defence.
Incident Response Has To Exist Before the Incident
A written incident response plan is one of the clearest dividing lines between prepared teams and exposed teams. The plan doesn't need to be long. It needs to be actionable.
At minimum, define:
Who declares an incident
Who leads technical triage
Who owns the legal and privacy escalation
Who communicates with customers and partners
How evidence is preserved
How access is revoked or contained
How recovery decisions are approved
In Canadian contexts, this matters because breach obligations aren't optional once the triggering conditions are met. A team that has to invent its workflow mid-incident loses time exactly when time matters most.
Rehearsal Changes Behaviour
Tabletop exercises often feel secondary until a real event exposes the gaps. Then the gaps are obvious. The security lead doesn't know who owns customer communication. Engineering doesn't know whether to shut off a partner integration. The product wants to keep the service alive. Legal wants confirmation that nobody can yet provide.
Run scenarios that reflect your actual platform. Compromised support account. Token leakage. Misconfigured export. Third-party API compromise. Cloud storage exposure. If the exercise never reaches operational tension, it's too abstract.
The teams that respond well usually share one trait. They've already argued about hard decisions before they had to make them under pressure.
Considering the Human Side of Security and Usability
A secure control that patients or clinicians can't use reliably doesn't stay secure for long. People route around it. Staff share devices informally, reuse sessions, or push work into email and spreadsheets. Patients abandon onboarding or stop consenting with a real understanding. That's not a usability issue on the side. It's a security failure.

Guidance in health systems and AI increasingly stresses that trust, representation, and transparency matter, and that biased inputs or weak community involvement can worsen disparities. It also highlights a problem many security teams ignore: strong controls can unintentionally reduce access for older adults, rural patients, or multilingual populations, which means secure design has to preserve accessibility, explainability, and informed consent rather than focus only on fraud prevention (health equity and trust considerations).
Friction Should Be Targeted, Not Universal
Not every workflow deserves the same level of interruption. A patient checking an appointment reminder shouldn't face the same challenge pattern as an administrator exporting sensitive records.
That's why good security design uses context:
Step-up authentication for high-risk actions
Clear consent language before data sharing
Accessible recovery paths for locked-out users
Support for multilingual and lower-literacy journeys
Session behaviour that reflects real care settings, not ideal office conditions
Fairness Belongs in Security Design
Security teams don't always think in terms of equity, but they should. If your identity proofing assumes stable broadband, current ID documents, and high digital confidence, some users will be excluded. If your consent experience is legally complete but cognitively dense, some users will agree without understanding.
The safest workflow on paper may be the least safe one in practice if users can't complete it correctly.
Secure healthtech applications have to protect people without inadvertently screening some of them out. That means design reviews should include accessibility, language clarity, recovery support, and community context alongside control strength.
Frequently Asked Questions About Healthtech Security
A product team ships an MVP, signs its first clinic, and then gets a security questionnaire that cuts across architecture, privacy, vendor access, logging, breach handling, and data residency in one document. That moment catches teams that treated security as a checklist. In healthtech, the work has to hold together across the full lifecycle, especially if you operate in Canada or move data across borders.
Does a Canadian healthtech app need to think about PIPEDA from day one?
Yes.
For Canadian healthtech products, privacy and security obligations shape design decisions early. The practical question is not whether to consider PIPEDA. It is whether the team has identified what personal information enters the system, where it is stored, which vendors can touch it, and what safeguards match that exposure.
I have seen teams lose time and money by postponing those decisions until procurement or enterprise sales. By then, data flows are already embedded in the product and hard to change safely.
Is encryption enough to call an app secure?
No. Encryption covers part of the problem. It protects data at rest and in transit, but it does not control account misuse, excessive privileges, weak consent handling, unsafe exports, or poor audit trails.
A secure healthtech application needs those controls to work together. Data protection, identity, authorisation, monitoring, vendor oversight, and recovery planning all have to line up. That is the difference between a control set and an operating model.
When should a startup invest in formal security processes?
Earlier than founders usually expect. A prototype does not need an enterprise ceremony, but it does need documented decisions on access roles, secrets handling, log retention, data minimisation, and incident ownership before real patient or provider data starts to accumulate.
Security gets expensive when the first serious review uncovers design debt. Early discipline is cheaper than reworking core flows after launch.
How should teams handle cross-border expectations?
Start with the strictest practical control set that fits the way the product operates. Then make that visible in architecture, contracts, and day-to-day operations.
Cross-border healthtech products often struggle in the same places: consent boundaries, data residency expectations, transmission security, support access, and auditability. One shared control framework usually works better than maintaining a Canadian version of the truth and a separate version for everyone else.
What’s the biggest mistake in vendor security reviews?
Treating the review as paperwork instead of system design.
A useful vendor review answers four operational questions. What data does the vendor receive? What actions can the vendor perform? How will that activity be logged and monitored? How do you suspend or replace the vendor without breaking care delivery or exposing data during the transition?
If those answers are vague, the review is incomplete.
What should a small team read when building health sector controls?
Small teams usually need practical reference material, not abstract policy summaries. This expert guide for health sector security is a useful supplementary read for teams that want another operational view of protecting healthcare information systems.
How do you know your security model is working?
Look for operational proof.
Can the team review access without manual chaos? Can investigators trace sensitive actions to a person, service, or integration? Can you disable a risky connection quickly? Can you restore safely after an incident? Can support staff do their jobs without broad visibility into patient records? Can users complete security-sensitive tasks without creating constant lockouts and workarounds?
If those answers are mostly yes, the model is doing its job. If they are mixed, the weak point is usually execution, ownership, or system coupling rather than policy language alone.
If your team is planning or rebuilding a health platform and needs help turning compliance, architecture, DevSecOps, and operational security into one delivery model, Cleffex Digital Ltd works on custom software and healthcare-focused application development that can support that kind of implementation.







