



Your claims platform probably isn't one system. It's a claims core, a policy admin platform, billing, payments, document management, fraud tools, CRM, perhaps a broker portal, and at least one spreadsheet that no one wants to admit is operationally critical.
That's why claims system integration rarely fails because of connectors alone. It fails when teams pick a pattern too early, underestimate hidden business rules, and discover too late that “claim”, “policy”, “customer”, and “payment ready” mean different things in different systems. If you're an IT Director planning a replacement, a modernisation programme, or a targeted integration around FNOL, adjudication, or payment, the important question isn't just which tool to buy. It's how data should move, where logic should live, and which compromises your organisation can sustain.
Why Disconnected Claims Systems Are Costing You Money
A familiar scene plays out in many claims operations. An adjuster opens the claims core to review a file, switches to the policy system to verify coverage, checks a document repository for supporting records, and then sends an email to finance because payment status sits somewhere else. While that happens, another employee rekeys the same claimant details into a portal or spreadsheet because the systems don't trust each other.
That friction looks administrative. It's financial.

Poor integration creates three expensive patterns. First, claims arrive with incomplete or inconsistent data. Second, staff spend time validating information that should already be available. Third, payment and exception handling slow down because each downstream team works from a slightly different version of the truth.
Where the Money Actually Leaks
The scale of the problem is hard to ignore. $260 billion is wasted annually on denied claims alone, and up to $32 billion is lost annually in administrative inefficiencies, according to claims payout statistics compiled by Talli. The same source notes that automation can reduce claims processing time by 50%.
Those figures matter because integration is what makes automation usable. Workflow software on top of disconnected systems usually automates the wrong thing. It speeds up hand-offs, but it doesn't fix broken data ownership, duplicate validation, or contradictory business rules across policy, claims, and finance.
Practical rule: If a claims handler has to ask, “Which system is correct?”, you don't have an interface problem. You have an operating model problem.
Why Integration Should Be Treated as a Business Programme
Claims system integration is often budgeted as middleware, APIs, and vendor services. That framing is too narrow. The fundamental business case is reduced denial burden, fewer manual touches, cleaner adjudication, and faster payment decisions.
Teams that are evaluating operational improvements often benefit from practical examples outside insurance-specific tooling as well. The implementation patterns described by F1Group on Dynamics 365 integration are useful because they show how integration decisions affect process design, not just data transport.
A similar point applies if you're considering workflow automation as part of the broader roadmap. This guide on insurance claim automation strategies is useful because it connects automation outcomes to the underlying system dependencies that have to be fixed first.
The Issue Isn’t Age Alone
Legacy platforms get blamed for most integration problems. Sometimes that's fair. Often, the bigger issue is that organisations have layered custom logic onto old and new systems for years, and no one has documented which system owns which decision.
That's why replacing one platform without redesigning the integration approach usually preserves the same delays in a newer interface. Claims teams still chase documents. Finance still reconciles exceptions manually. Supervisors still manage workarounds instead of service levels.
Defining Your Integration Objectives and Use Cases
Before anyone debates APIs versus batch, define what the integration must accomplish in business terms. Otherwise, the project gets shaped by whichever vendor gives the best demo.

Most organisations start with broad goals like “faster claims handling” or “better customer experience”. Those are valid, but they're too vague to guide architecture. Integration objectives need to be tied to a process stage, a decision point, and a measurable operational outcome.
Start With the Moments That Break Flow
Useful use cases usually sit where teams currently stop and verify something manually. In claims, those pressure points tend to be:
FNOL intake: Data enters through a portal, call centre tool, broker channel, or partner feed and must be validated against policy and party records.
Coverage and eligibility checks: The claims platform needs current policy, endorsements, limits, waiting periods, or benefit rules at decision time.
Document and evidence handling: Medical records, photos, estimates, repair data, and correspondence must be tied to the right claim and made accessible across teams.
Payment readiness: Claims approval, reserve updates, tax logic, fraud checks, and payment instructions all have to align before funds move.
Fraud and exception routing: Suspicious claims need enriched data and routing rules, not just a flag.
If you can't list the exact hand-off where the business loses time or confidence, the project is still too abstract.
Tie Objectives to Outcomes People Care About
Integrated claims systems can produce material operational gains when implemented properly. Healthcare providers and insurers report a 25% improvement in first-pass claim acceptance rates and can accelerate reimbursements by up to 10 days, according to Fortune Business Insights on the claims management market.
That doesn't mean every integration initiative should aim at the same result. It means your objectives should connect directly to acceptance, reimbursement, exception handling, or straight-through processing rather than generic platform modernisation language.
A practical objective set might look like this:
Reduce rekeying at FNOL: Eliminate duplicate claimant and policy entry across intake and claims systems.
Improve adjudication quality: Ensure handlers see policy status, prior claims context, and required documents in one workflow.
Shorten payment hand-off: Push approved claims to finance with complete, validated payment payloads.
Support self-service without manual clean-up: Let customers or brokers submit information once, then reuse it downstream.
The best integration objective is narrow enough to test and broad enough to matter financially.
Separate Executive Goals From Architectural Use Cases
Leaders usually approve funding because of service, cost, and control. Architects need a second layer that translates those goals into system behaviour. For each objective, define:
Trigger
What event starts the exchange? A new FNOL, status change, approved reserve, uploaded document, fraud score, or payment authorisation.Source of truth
Which system owns the data at that moment? This should be explicit, especially for customer, policy, reserve, and payment fields.Latency requirement
Does the process require real-time response, near-real-time propagation, or a scheduled batch?Failure handling
If the target system is down or validation fails, who gets notified, and how is the work recovered?
These questions usually expose hidden scope. They also prevent the common mistake of treating every use case as if it needs immediate synchronous integration.
For teams building the business case, implementation-oriented material like Bridge Global insurance automation whitepapers can help frame process-level opportunities and clarify where automation depends on reliable integration rather than replacing it.
Choosing the Right Claims Integration Pattern
Most integration discussions start with tooling. They should start with flow characteristics. Are you moving a claim transaction that must return a decision immediately? Publishing status changes to several downstream systems? Sending nightly payment files? Exposing reusable services to portals and partners?
Those are different problems. They need different patterns.
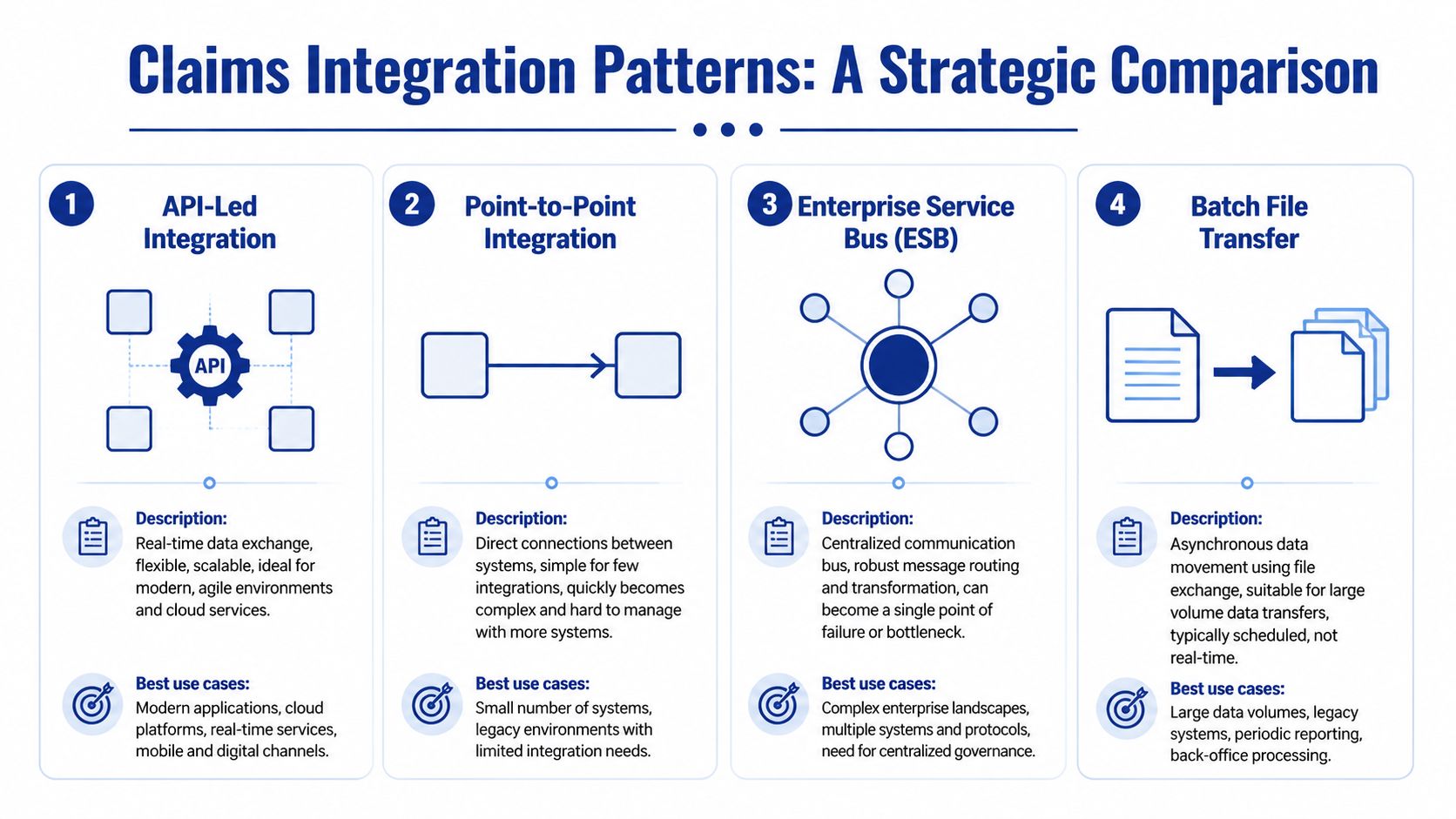
The Main Patterns and Where They Fit
The useful patterns in claims system integration are usually API-led integration, ESB-based orchestration, iPaaS-mediated cloud integration, and event-driven messaging. Batch file transfer still matters as a supporting mechanism, but it's usually best treated as a tactical pattern for specific data exchanges rather than the backbone of a modern operating model.
Here's a practical comparison.
| Pattern | Best For | Pros | Cons |
|---|---|---|---|
| API-led integration | Real-time validation, portal access, reusable services across policy, claims, and billing | Clear contracts, fast response, good fit for modern platforms, easier reuse | Can become chatty, requires strong API governance, not ideal for every high-volume asynchronous flow |
| ESB | Large enterprises with many legacy systems and complex routing or transformation rules | Centralised mediation, strong transformation capability, supports legacy protocols | Governance can become heavy, bus logic often grows into a bottleneck |
| iPaaS | Mid-market organisations, SaaS-heavy estates, faster delivery needs | Faster implementation, prebuilt connectors, lower operational overhead than custom middleware | Limited flexibility for unusual logic, vendor constraints can shape architecture |
| Event-driven messaging | Status propagation, decoupled workflows, scalable claim lifecycle notifications | Good resilience, supports multiple subscribers, fits high-volume state changes | Harder to debug, demands disciplined event design and idempotency controls |
What the Canadian Benchmarks Suggest
For Canadian insurers, the benchmark data strongly favours disciplined modernisation over ad hoc interfaces. API-first integration projects can reduce claims leakage by 7 to 14%, and carriers using middleware iPaaS achieved 85% end-to-end straight-through processing within 12 months compared with 45% for those using ad hoc integrations, according to Genasys on hidden insurance integration cost.
That's an important distinction. The win isn't “APIs are always best”. The win is planned, standardised integration with explicit data mapping and mediation discipline. I've seen organisations choose APIs as a slogan and still implement brittle point-to-point connections because every team exposes slightly different contracts and naming conventions.
How To Choose the Pattern
The right pattern depends on four operational questions.
When Does the Business Need an Answer?
If a portal user submits FNOL and needs immediate eligibility feedback, use synchronous APIs. If the claims core publishes a reserve update and several other systems need to react on their own timelines, event-driven messaging is usually a better fit.
A simple rule works well here. Use APIs when a caller needs a direct response. Use events when a system needs to announce that something has happened.
Where Should Orchestration Live?
Many programmes struggle at this specific stage. Teams place business orchestration within the integration layer for convenience, but this often creates confusion. Consequently, it becomes unclear whether the claims core, middleware, or portal owns the adjudication sequence.
Keep orchestration close to the business domain unless there's a strong reason not to. Integration layers should route, validate, transform, enrich, and observe. They shouldn't become your hidden claims application.
Don't let middleware become the place where undocumented claim rules go to hide.
How Much Legacy Complexity Do You Need To Absorb?
If your estate includes older policy admin platforms, billing engines, file-based partner exchanges, and non-standard interfaces, an ESB or hybrid iPaaS plus message broker approach may be more realistic than a pure API strategy.
If your environment is mostly SaaS and modern cloud applications, iPaaS can speed delivery and reduce custom plumbing. That speed matters, but only if your team still controls canonical definitions and error handling instead of outsourcing both to connector defaults.
How Many Future Consumers Do You Expect?
A direct link between claims and billing may look efficient today. It becomes expensive when finance, data, fraud, customer service, and partner systems all need the same information later. That's where API products and event streams create reuse.
Teams evaluating broader application design choices often benefit from reviewing enterprise application architecture patterns because claims integration decisions are rarely isolated from the wider application environment.
What Usually Works in Practice
For many insurers, the most durable model is hybrid:
APIs for inquiry, validation, and command-style interactions
Events for status changes and downstream notifications
iPaaS or ESB capabilities for protocol mediation, transformation, and partner connectivity
Batch only where timing and business tolerance allow it
What doesn't work well is pretending one pattern can solve everything. It can't. Claims operations are too varied. FNOL, adjudication, fraud review, document ingestion, and payment settlement don't behave the same way, so they shouldn't be integrated the same way.
Mastering Data Mapping and Transformation Logic
Most integration failures that look technical are really mapping failures. The interface runs. Messages arrive. Then the business starts finding claims in the wrong queue, payments missing tax context, duplicate parties, or closed claims reopening because one status code means “paid” in one system and “approved for payment” in another.
That's why field mapping is the smallest part of the job. The difficult part is semantic mapping.

Build a Canonical Model, but Keep It Honest
A canonical data model gives the programme a shared language for claims, policy, parties, coverages, reserves, payments, documents, and events. Without it, every source-target pair becomes a one-off translation exercise.
But many canonical models fail because they're too abstract. They describe ideal entities and ignore the messy operational states that people use. A useful claims canonical model has to represent things like pending coverage review, partial documentation, reopened claims, subrogation indicators, and payment exceptions.
Start with core domains:
Claim with identifiers, type, status, dates, and loss context
Policy with product, coverage references, status, and effective periods
Party for claimant, insured, broker, provider, and payee
Financials for reserve, benefit, adjustment, recovery, and payment
Documents and evidence with source, type, and lifecycle state
Events such as a claim lodged, a document received, an approval granted, and a payment released
Map Rules, Not Just Fields
A bad mapping workshop sounds like this: “Field A goes to field B.” A good one asks what business meaning changes in transit.
Examples of hidden logic that often break claims integrations:
Status translation: One platform uses a single status for “open”, while another separates intake, triage, investigation, approved, settled, and closed.
Party resolution: A legacy system stores one free-text customer name field, while the target needs legal name components and role-specific party relationships.
Code harmonisation: Province, benefit type, denial reason, and payment method codes often differ across systems.
Date interpretation: Loss date, reported date, received date, and adjudication date may all be present, but teams use them differently in reports and SLAs.
Financial rounding and sign rules: Credits, recoveries, offsets, taxes, and reserve movements can invert or split values between systems.
If your mapping document doesn't capture business assumptions, it's only a spreadsheet of guesses.
Use Discovery Artefacts That Force Clarity
Strong mapping work usually depends on a few unglamorous artefacts:
Source-to-canonical workbook
One sheet per source system. Include field origin, data type, valid values, optionality, ownership, and business notes.Canonical-to-target workbook
Define what the receiving system expects, including conditional rules and default behaviour.Decision table for transformations
Status, routing, tax, and eligibility logic belong here in plain language.Exception catalogue
List what happens when mandatory fields are missing, values conflict, or records can't be matched.
This work is tedious. It's also where projects are won.
Clean Data Before You Integrate Volume
Trying to solve data quality only in the middleware is expensive. Integration can validate and quarantine. It can't magically resolve longstanding ambiguity in customer identity, policy references, or historical duplicate claims.
Practical teams do three things early. They profile live data, identify fields with genuine business risk, and force owners to approve remediation rules before the first production cutover. They also test mappings with awkward real examples, not only neat sample records.
The hidden business logic challenge in claims system integration isn't translating data. It's deciding which interpretation the business is prepared to standardise.
Navigating Security Compliance and Testing
Claims data is unusually sensitive because it combines personal information, financial details, medical context in some cases, and operational decisions that affect payment. Integration multiplies the exposure because data now moves across APIs, queues, connectors, logs, cloud services, and vendor-managed components.
That means security design can't be bolted on after the interfaces work. It has to shape the integration architecture from the start.
Security Controls That Fit Claims Integrations
Teams typically understand the technical basics: strong authentication, authorisation by role and purpose, encryption in transit, encryption at rest, secret management, and audit logging. The mistake is treating those controls as purely platform concerns.
In claims operations, you also need to decide which systems are permitted to see which fields at which stage. A portal may need claim status, but not internal fraud indicators. A finance integration may need payment instructions, but not investigative notes. A repair partner may need document access for one claim, not a broad customer history.
A layered security mindset helps here. Material on defence-in-depth strategies for Houston SMBs is useful because the principle applies cleanly to claims integration as well. Don't rely on one control. Use layered controls across identity, transport, application logic, data access, monitoring, and recovery.
The Canadian Compliance Angle Is Operational, Not Abstract
In Canada, privacy and data-handling obligations affect design choices around storage, access, retention, and auditability. The practical issue isn't only whether your systems are compliant on paper. It's whether an integrated workflow exposes claimant data in places the business didn't intend.
Bilingual operations add another layer of risk. A 2025 survey of Quebec carriers found that 74% struggle with API integrations for real-time analytics on French-language claims, delaying fraud detection by 15 to 20 days compared with English workflows, according to Riskonnect on modern claims management and straight-through processing.
That matters beyond analytics. Language handling affects document classification, searchability, workflow routing, and the evidence used by fraud or adjudication models. If French-language claims are processed differently because metadata or extracted content behaves differently, you don't just have a feature gap. You have a control gap.
For a broader sector lens, this article on cybersecurity in the insurance industry is a useful reference point when evaluating risk exposure around connected insurance platforms.
Security testing should prove that only the right data moves to the right place, not just that the endpoint returns a valid response.
Build Testing Around Business Failure Modes
Claims integration testing needs more than unit tests and API happy-path checks. It needs scenario-based validation that mirrors how operations fail.
Use at least these layers:
Component tests for transformations, authentication, routing, and retries
Contract tests to catch schema drift between producers and consumers
Integration tests across actual connected systems in a production-like environment
Negative tests for missing documents, invalid codes, duplicate claims, stale policy status, and timeout conditions
User acceptance tests driven by claims, finance, and compliance users, not only IT
A mature testing plan also checks observability. Can the support team trace a claim event end-to-end? Can they see which transformation rule fired? Can they distinguish a transient outage from a business validation failure?
Testing starts when the first mapping is drafted, not the week before go-live.
Planning Migration Cutover and Monitoring
Go-live is where architectural confidence meets operational reality. A clean test cycle doesn't guarantee a smooth cutover because production introduces real volume, live users, timing overlaps, and exceptions that no scripted scenario fully reproduces.
That's why cutover planning for claims system integration should be treated as an operational change programme, not a deployment window.
Choosing Between Big Bang and Phased Rollout
A big bang cutover can work when the integration scope is narrow, the business can tolerate concentrated risk, and rollback is feasible. It's attractive because it avoids prolonged dual-running and reduces the confusion of operating two modes at once.
A phased rollout is usually safer for claims environments with multiple products, regions, partner channels, or payment dependencies. You can phase by claim type, business unit, distribution channel, or lifecycle stage. The best phasing model is the one that contains failure without creating endless temporary logic.
Use these decision criteria:
Operational coupling: If payment, reserves, and policy validation are tightly linked, broad cutover raises the blast radius.
Data synchronisation difficulty: If two systems can't remain aligned easily during transition, prolonged coexistence may be more dangerous than a short cutover.
Support readiness: If business and IT support teams are new to the solution, a phased rollout gives them room to learn.
Vendor dependency: If defect turnaround depends on multiple vendors, avoid a compressed cutover unless escalation paths are proven.
Design Rollback Before Finalising Go-Live
Rollback plans are often superficial. “Restore backups” isn't a business rollback strategy. In claims, you need to know how to unwind or continue claims already touched by the new integration.
A workable rollback plan answers questions such as:
What happens to claims created during the cutover window?
Can payments initiated through the new path be safely halted or reconciled?
Which system becomes authoritative if synchronisation breaks mid-cutover?
How will users know which claims are in which state?
If the team can't answer those questions, the programme isn't ready for a risky cutover.
Monitor Business Signals, Not Only Technical Ones
Post-go-live dashboards often focus on API latency, queue depth, throughput, and error rates. Those are necessary, but they're not enough. A technically healthy interface can still create a business failure if it routes claims to the wrong queue, suppresses a required document, or produces incomplete payment instructions.
Track both technical and operational indicators:
Technical health: latency trends, failed transactions, retry volume, dead-letter activity
Business flow: claims stuck in review, document mismatch exceptions, payment rejection counts, duplicate party creation, and manual intervention queues
Support visibility: top recurring error categories, unresolved incidents by age, and affected business functions
A stable integration is one that the business can trust during a Monday morning surge, not one that passed last week's deployment check.
Put Ownership in Writing
Monitoring only works when ownership is explicit. Someone must own API uptime. Someone must own mapping defects. Someone must own operational exception handling. Someone must own communication with claims and finance users.
The most effective operating models define runbooks for common failures, escalation thresholds, and business-facing incident language before launch. That avoids the usual pattern where IT reports “message processing degraded” while claims teams only know that work has stopped.
Your Integration Checklist and Vendor Selection Guide
By the time you're comparing vendors, many strategic decisions should already be made internally. A partner can help shape architecture and delivery, but they shouldn't be the first group to define your claims operating model for you.
Use the checklist below to pressure-test readiness before procurement or implementation starts.
Integration Checklist for Claims Programmes
Business outcomes are defined: You've documented which claims processes need to improve and how the business will recognise success.
Use cases are prioritised: FNOL, adjudication, fraud review, payment, document management, and reporting needs are ranked by business impact.
System ownership is clear: For each major data object, you know the source of truth and the consumers.
Pattern decisions are intentional: You've chosen where APIs, events, iPaaS, ESB capabilities, or batch belong, and why.
Canonical definitions exist: Claim, policy, party, payment, document, and status models have been agreed across teams.
Transformation logic is documented: Mapping rules include business conditions, defaults, code translations, and exception handling.
Security design is embedded: Access, auditability, data minimisation, and secret management are built into the architecture.
Testing covers real scenarios: The plan includes failure cases, bilingual or regional variations, user acceptance, and support observability.
Cutover strategy is realistic: Rollout sequence, rollback logic, support model, and communication plans are documented.
Operational ownership is assigned: Monitoring, incident response, release management, and post-go-live support all have named owners.
If even a few of those items are missing, a slick vendor demo can hide a lot of delivery risk.
Questions To Ask Any Integration Partner
A capable vendor should answer these directly and concretely.
How Do You Choose an Integration Pattern for a Claims Use Case?
You want to hear decision criteria, not product preference. A strong answer will distinguish synchronous transactions, event propagation, legacy mediation, and batch constraints. A weak answer will force every use case into the same platform shape.
Where Will Business Logic Live?
This is one of the most important questions in the whole selection process. Ask the vendor to explain which rules belong in the claims platform, which belong in middleware, and how those rules will be documented and governed.
How Do You Handle Mapping and Data Quality?
Ask to see sample artefacts such as mapping workbooks, canonical models, decision tables, and exception catalogues. If the partner speaks only about connectors and not about semantics, expect trouble later.
What Does Testing Look Like Beyond the Happy Path?
Look for a delivery approach that includes negative scenarios, production-like data volumes, user-driven acceptance, and support readiness. Ask who writes the test cases for business exceptions.
What Happens After Go-Live
Many teams underestimate operational support. Ask how the partner handles monitoring, release coordination, defect triage, and knowledge transfer to internal staff.
The right vendor doesn't just promise integration speed. They reduce ambiguity where claims operations are most likely to break.
Red Flags During Selection
Some warning signs appear early:
Tool-first selling: The conversation starts and ends with one platform.
No opinion on data governance: The vendor assumes source systems are clean enough.
Vague ownership boundaries: Nobody can explain where orchestration or validation rules will live.
Weak support model: Post-launch responsibility is unclear.
Generic insurance language: The partner can describe “claims transformation” but not the difference between intake validation, adjudication logic, and payment release.
The best integration partner will often slow the project down at the beginning. That's usually a good sign. Good teams ask difficult questions about ownership, semantics, and operating constraints before they start building.
If you're planning claims system integration and want a delivery partner that can handle architecture, custom software, automation, cloud, and secure data workflows, Cleffex Digital Ltd is worth a look. As a Canada-based software development company, they help organisations turn complex business processes into practical digital systems that are easier to operate, scale, and support.







